1. Lemmatizer
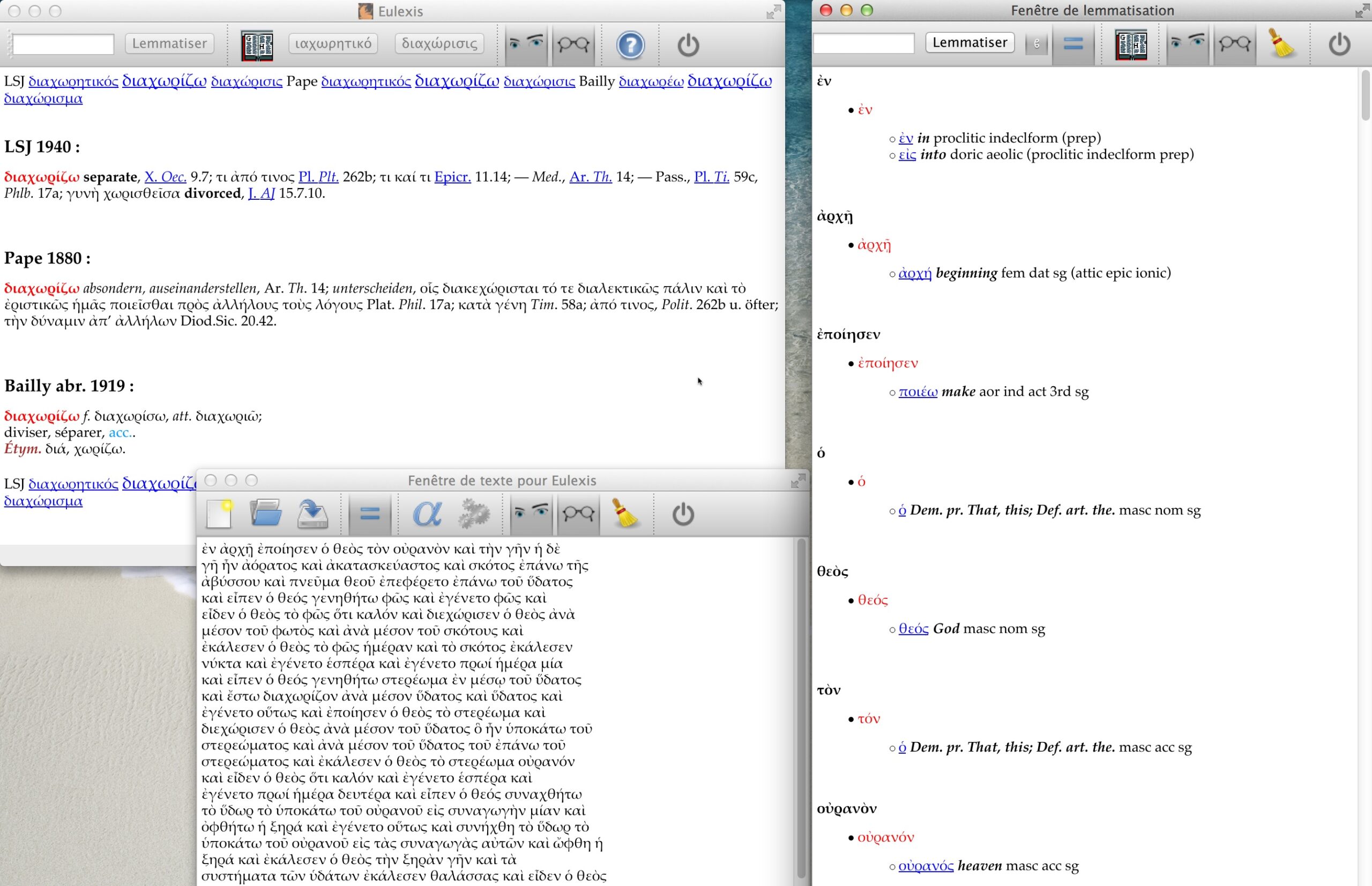
1.1 Form-Lemmatizer: Eulexis
The Greek words in the list are transliterated using betacode. To alleviate the problem of accent and breathing marks, these diacritic signs are not taken into account in the search of a form. The case of the iota subscript may be discussed, but, as it is encoded with a special character, it is treated as any other diacritic. Forgetting the “decoration” of the forms reduces their number to 853,000. In a case where the Greek word is typed with Latin characters, it produces a simple match. On the other hand, the search of a word that comes from a Greek text, with its diacritic signs, gives too many results. The exact match, if it exists, appears first and is red-colored. An option has also been introduced to show only this exact match, as seen in Figure 1.
1.2 Combining Lemmatizer: Collatinus
However, the lemmatization of a form requires the reverse process. For a given form, we have to split it in all the possible ways and to check that the first part coincides with a root and the last one with a known word-ending. And, obviously, we have also to check that the two parts fit together (i.e., that they are associated to the same paradigm with a proper matching rule). The word-endings carry part of the information for the analysis, which is then stored in the file. Instead of an explicit analysis as e.g., nominative singular, we just make a list of the morphosyntactical analyses that are possible in Latin and code the analysis with a simple number. As a matter of fact, there are only 416 of these analyses. The number is converted in its human readable form when needed, i.e., for the display as in Figure 2. By the way, this encoding allows also to translate the analysis into different languages. [10]
2. Other Features
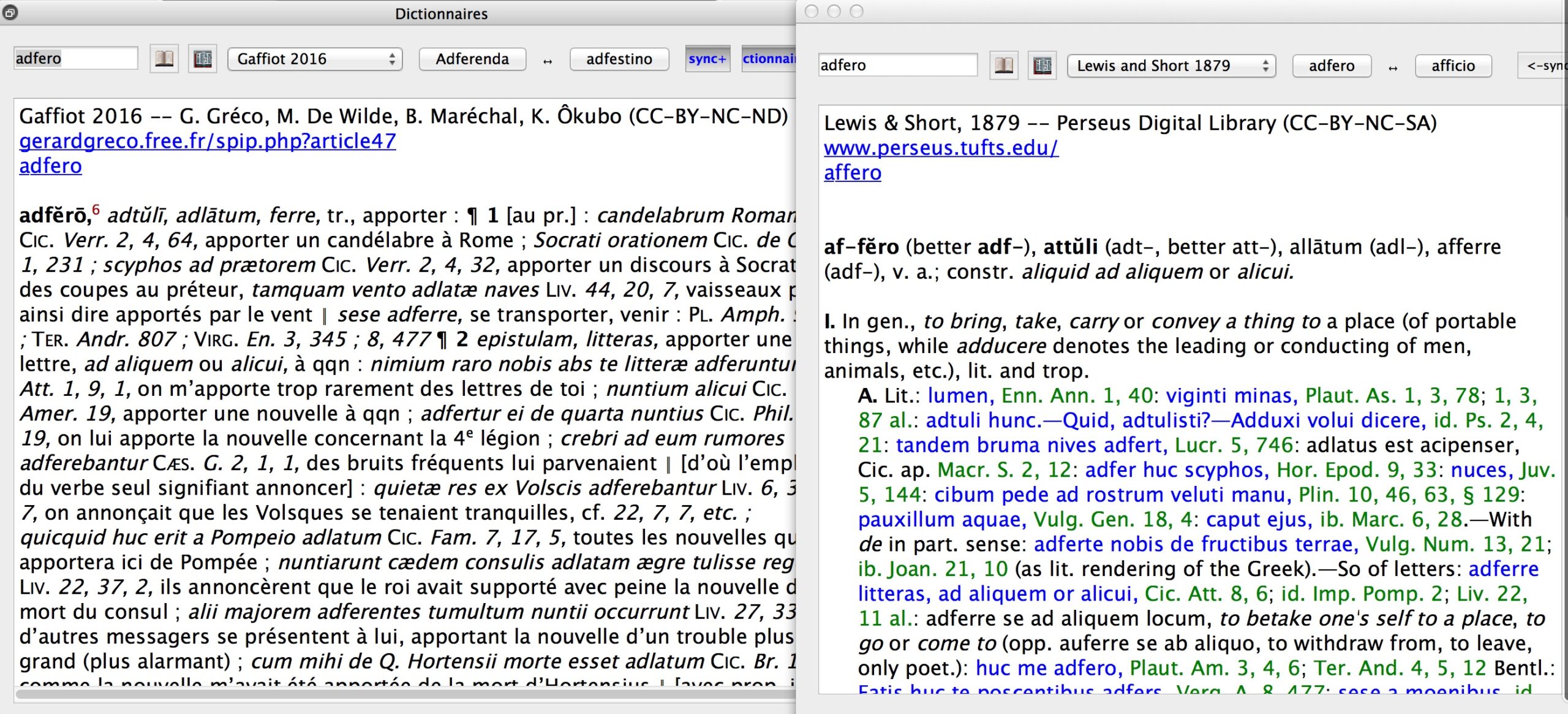
2.1 Opening Dictionaries
For the digital dictionaries, each article has been converted into HTML and compressed to save space on disk. When the user looks for a word in the dictionaries (two of them can be displayed simultaneously; an example is given in Figure 3), the program loads the corresponding articles, decompressing and displaying them. It is interesting to note that the shift from paper to digital display changes things. For instance, in L&S one finds the etymology of the word between square brackets that have been converted into XML with the tag <etym>. However, often the etymology of a word is the same as the one of the previous ones, which leads to the short form “[id.]” or, in XML, “<etym>id.</etym>.” On a full page, this is not a problem: the interested reader scans the page to get the correct etymology. If the display is restricted to the searched article, the short form of the etymology is useless. Thus we have made these etymologies explicit with a program.
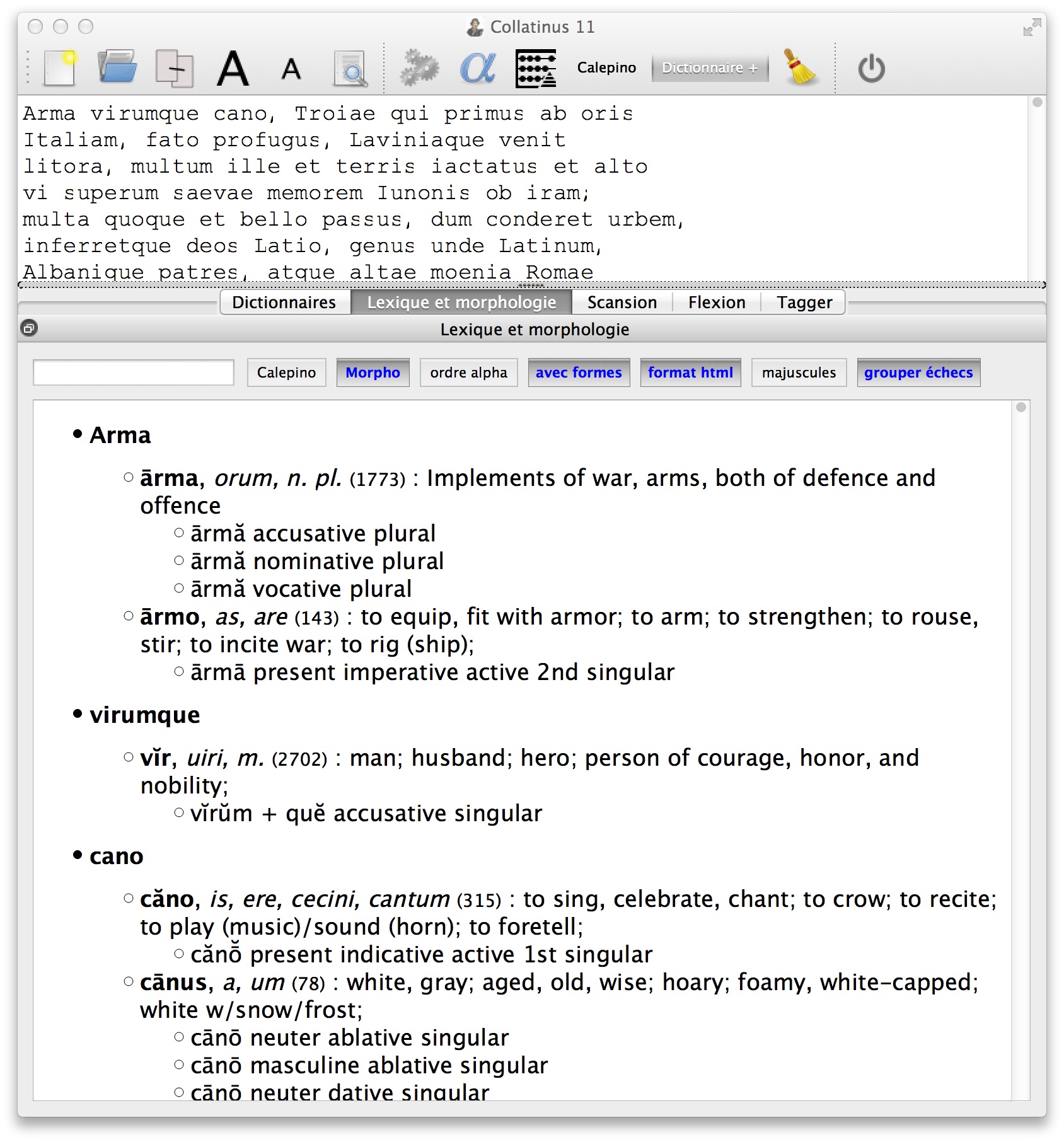
2.2 Scanning Latin Texts
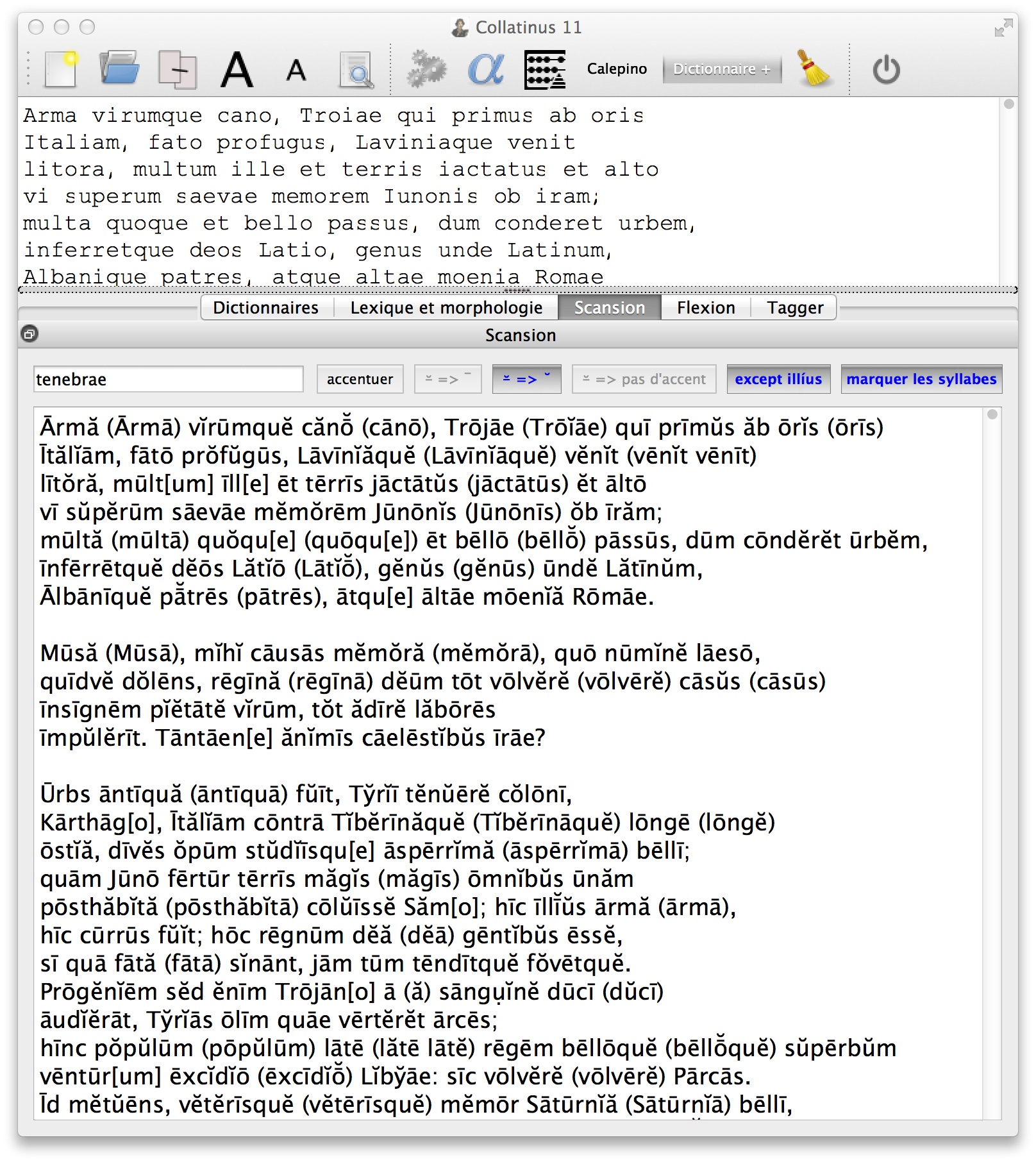
When scanning a text, Collatinus replaces the standard form found in the text, by its counterpart with the lengths indicated. When a form has several analyses, which give different lengths for the vowels, all the possible solutions are given. The first one is the most frequent as to the lemmatization (see 1.2.3 above). The others are written in parentheses. For instance, as seen in Figure 4, the first verse of the Aeneid becomes:
Knowing that this is a dactylic verse, it would be possible to choose the proper form and to separate the meters Ārmă vĭ / rūmquĕ că / nō, Trō / jāe quī / prīmŭs ăb / ōris. But we have chosen not to do so because it is too specific to dactylic verses. Pede Certo [42] does supply forms and meters in a fantastic way, and it has been used to scan about 244,000 verses. To be generalized, it would require that the program be able to disambiguate with enough accuracy to choose one of the possible scanned forms (see 2.3 below) and/or that it have some information about the used meter, to indicate the pauses for instance. On the other hand, if one knows that the verse is an hexameter, some solutions can be excluded: for instance, the indicative present vĕnĭt does not fit at the end of the second verse in Figure 4.
2.3 Disambiguation of Latin
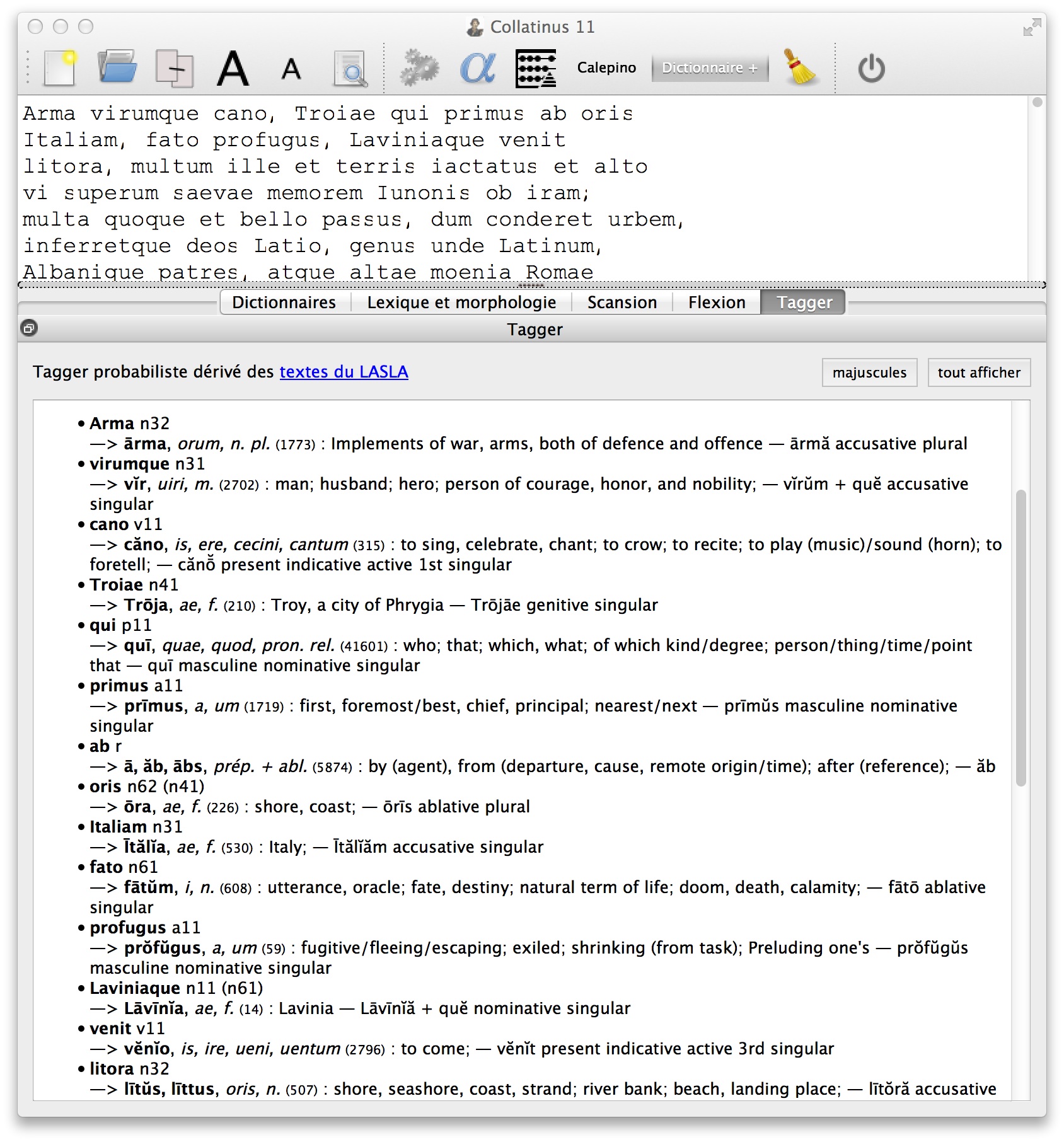
With this approximated value for the number of occurrences, it is possible to calculate the same probabilities as before. Instead of giving only the best solution, we propose the first two sequences of tags in terms of probabilities. Here, the tagging process is just intended to help the reader: it remains a lemmatization of the sentence or of the text, with a more sophisticated procedure to choose the best solution. [58] Obviously, it is not error-free: in the example of Figure 5, the “wrong choice” of the lemmatizer for oris has been corrected, but not the one for venit.
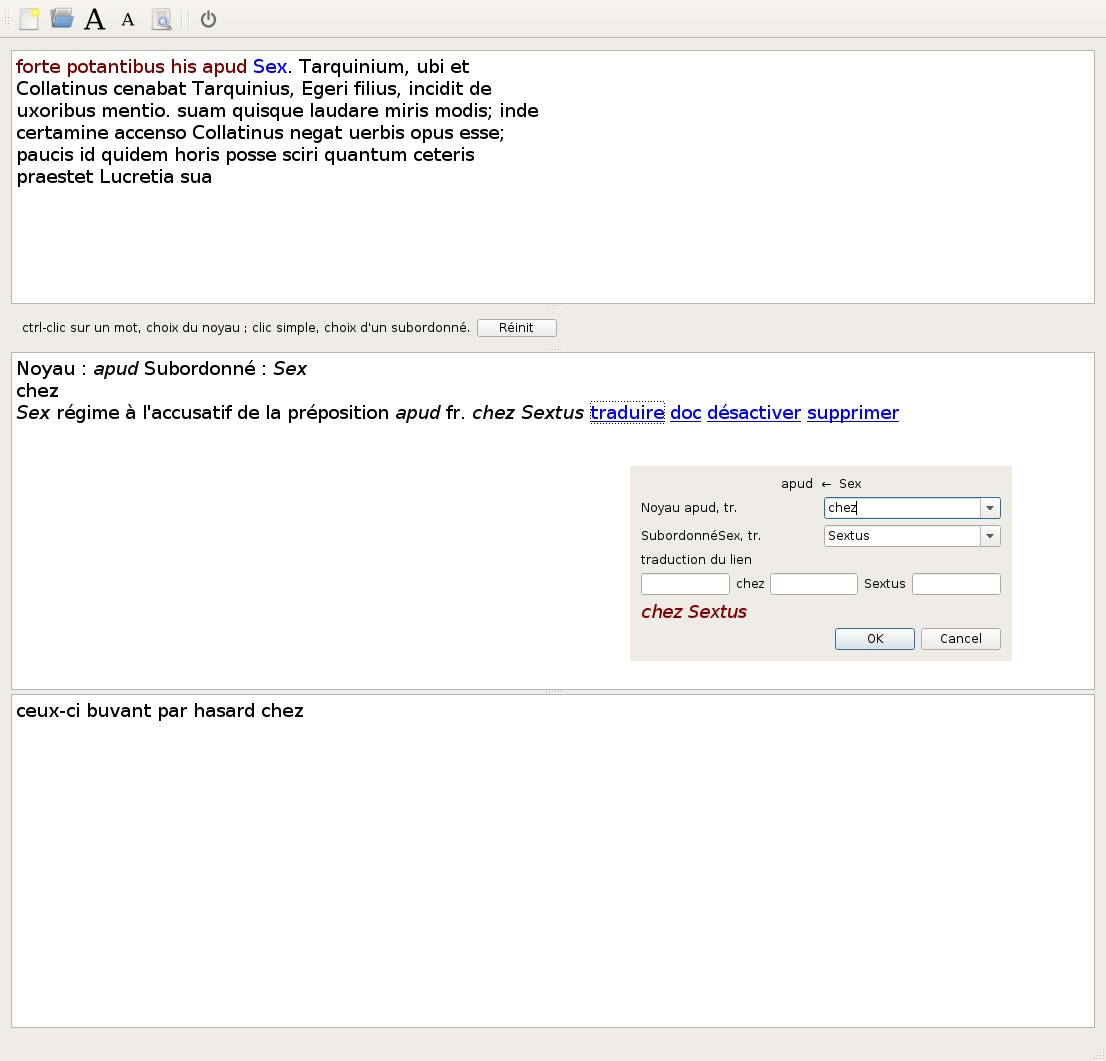
3. Further Developments
3.1 Praelector
For the interface, the screen is divided into three parts. At the top, the read-only Latin text is displayed. In the middle, the list of syntactic links appears. And below that, the translation is built gradually. The user selects, in the text, the governor and the dependent words, and the program proposes the links that could exist between these two words, together with an approximate translation of each link (see Figure 6). To do that, Praelector uses a set of rules recorded in a file. This file, which can be read and edited by any human being, gives for each link the morphologies of the governor and of the dependent, their relative position, some other constraints, and a translation in the target language. [61] The user can choose one link, edit its translation, and the translation of the sentence is automatically updated.