Overview
The Venetus A manuscript of the Iliad (Marciana 454 = 822) is uniquely important for Homerists. [1] The scholarly notes (or scholia) that often fill the margins of the manuscript’s pages cite scholars as early as the first Alexandrian editors of the Iliad, and in some cases quote them for readings of the Iliad not known elsewhere in the manuscript tradition. Between 2010 and 2018, the main focus of the Homer Multitext project (HMT) was to prepare digital editions of the texts in the Venetus A manuscript. In this paper, we first outline the design of our digital editions (Section 1), then show how this architecture supports new kinds of research. Specifically, we apply new methods to two classic problems.
- How should we interpret the physical organization of this uniquely rich manuscript? Can we identify the function of the carefully planned, distinct zones of the page layout? (Section 2)
- Can we find evidence for the work of antiquity’s most influential editor, Aristarchus of Samothrace? (Section 3)
Section 1
The Venetus A scholia
When is a digital document a digital edition?
Section 2
Analyzing layout and content in the Venetus A

One of the advantages of ToPan is that it produces a clear visualization of the topic modeling results, as illustrated in Figure 2.
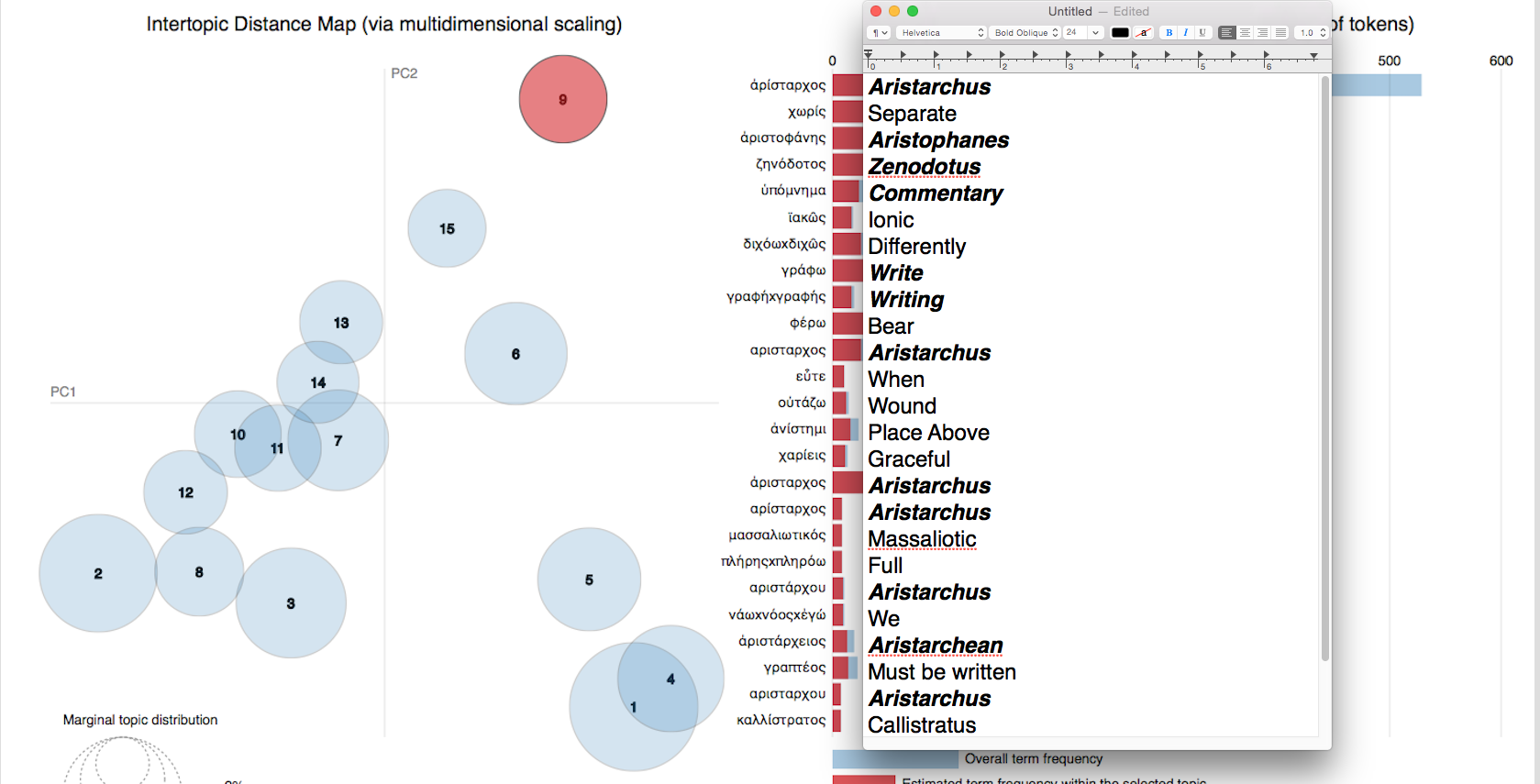
Table 1: Distribution of “Aristarchus” topic by zone compared to all scholia
| Zone | Total distribution in Venetus A | Distribution within “Aristarchus topic” |
| Main scholia (yellow) | 3597 (45.3%) | 45 (32.37%) |
| Intermarginal scholia (red) | 1219 (15.4%) | 65 (46.76%) |
| Interior scholia (blue) | 819 (10.3%) | 28 (20.14%) |
Section 3
Finding the language of Aristarchus
Defining a feature set
Aristarchan features:
- Critical sign
- γράφει (active)
- Initial ὅτι
- Higher topic 6 score
Post-Aristarchan features:
- παρὰ Ζηνοδότῳ
- Aristarchus’ name
- Post-Aristarchan name
- Higher topic 9 score