1. From Erasmus Novum Instrumentum omne to the Greek New Testament in digital culture
ftrumentum omne, diligenter ab ERASMO ROTERDAMO
recognitum & emendatum…
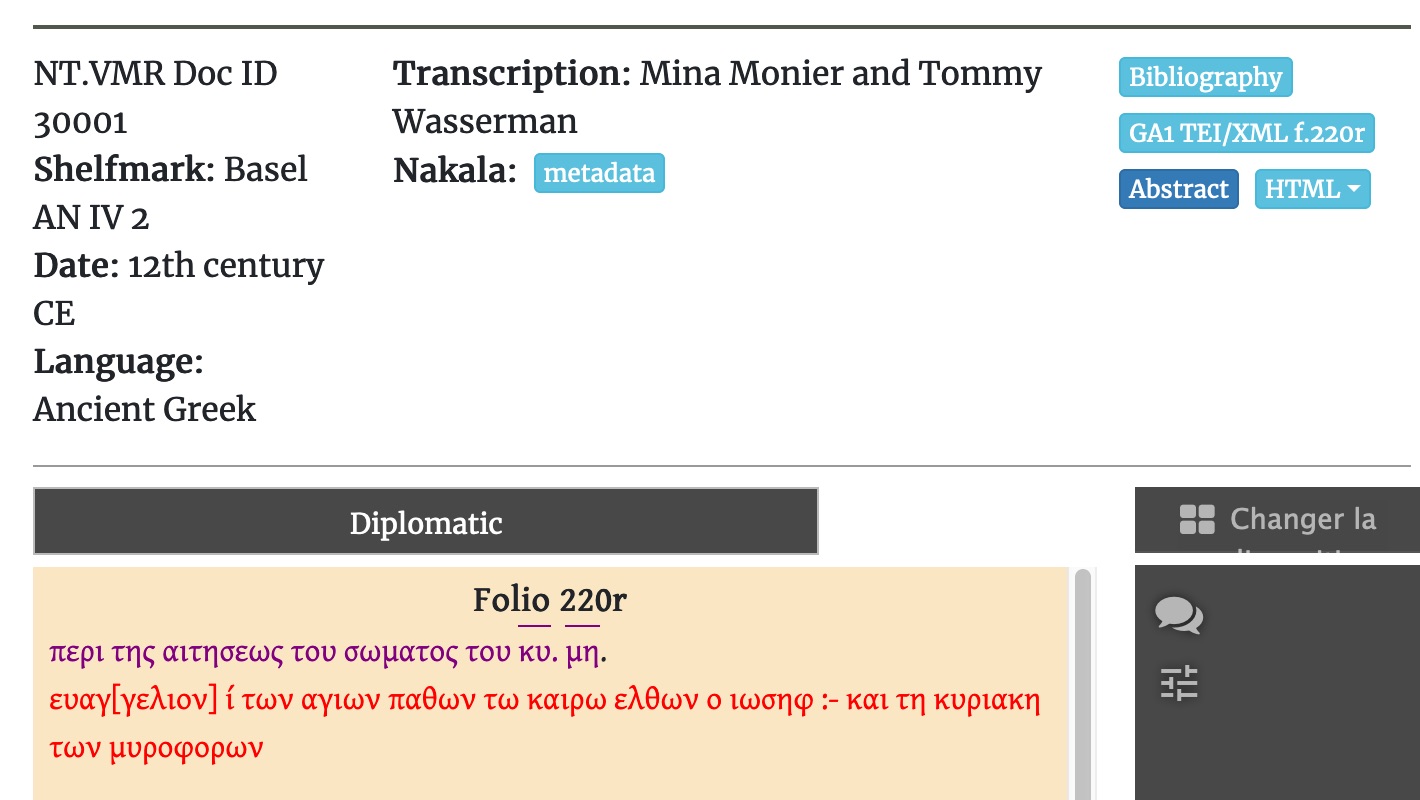 GA 1, f. 220r; transcription and encoding by Mina Monier with the collaboration of Tommy Wasserman for the marginal notes, [19] SNSF MARK16 ©CC BY-4.0. [20]
GA 1, f. 220r; transcription and encoding by Mina Monier with the collaboration of Tommy Wasserman for the marginal notes, [19] SNSF MARK16 ©CC BY-4.0. [20] 2. MARK16 as Virtual Research Environment (VRE): the manuscript room
2.1 MARK16 and the digital developments of the New Testament textual criticism
Based on this theoretical background, a 2019 publication has described the MARK16 VRE in detail, [31] but to summarize here, the MARK16 VRE is divided into four parts. The first one, the “Manuscript Room,” hosts a selection of manuscripts in Greek, Latin, and other ancient languages that are particularly significant for the study of Mark’s last chapter. The perspective is consequently not to gather all Mark 16 witnesses as it has been done for John 18 in the preparation of the John ECM, but to apply a close reading that sheds light on the complexity of this subject and to introduce new elements to this file. The second part, “Interpretations,” underscores the diversity of scholarly voices on Mark 16 through the use of a new multimodal editing tool, eTalks. [32]
2.2 The MARK16 manuscript room: how to reconfigure the relationship to NT textuality
 sa 393var transcription by Gregor Emmeneger and encoding by Mina Monier. SNSF MARK16 ©CC BY-4.0.
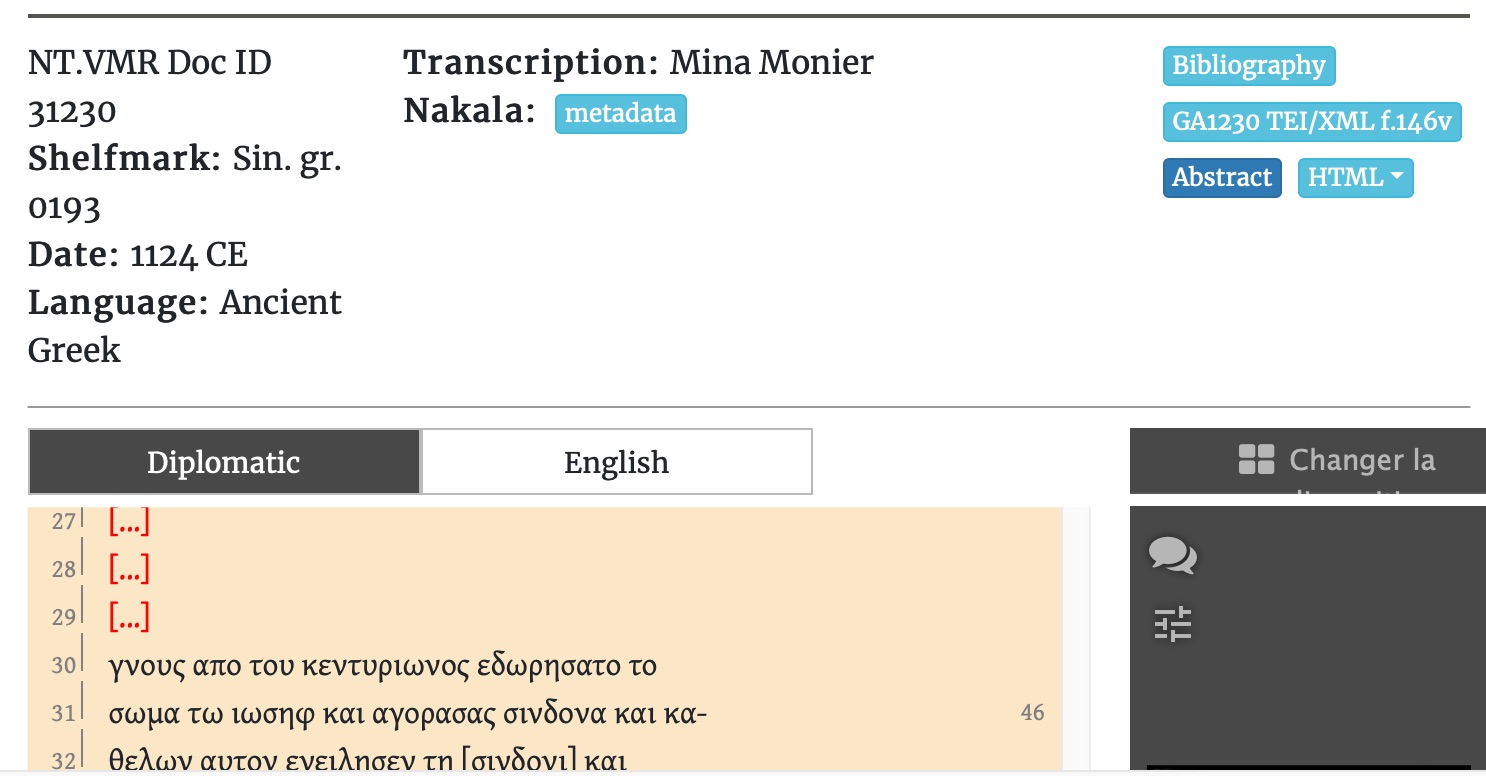
sa 393var transcription by Gregor Emmeneger and encoding by Mina Monier. SNSF MARK16 ©CC BY-4.0.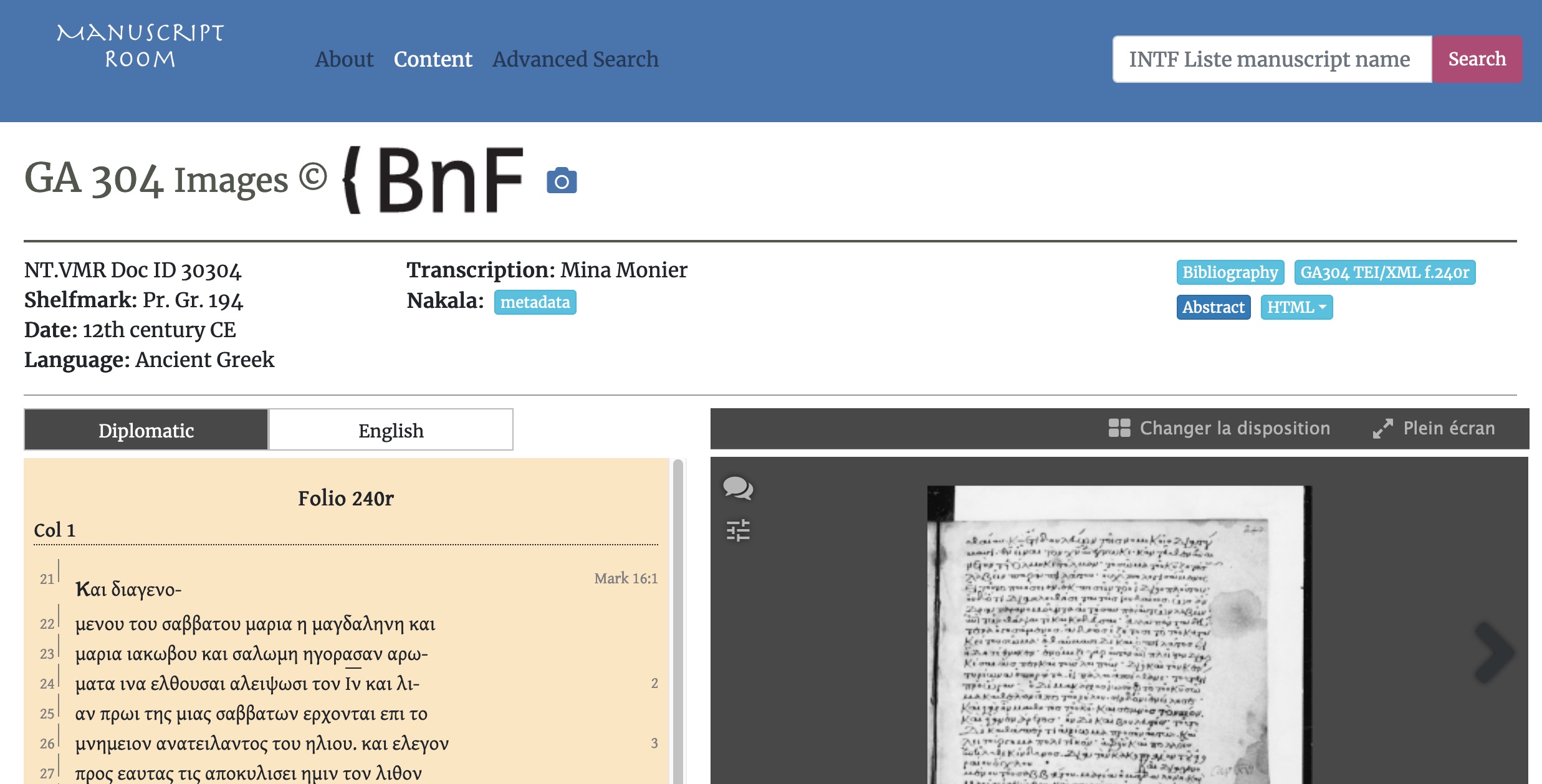 GA 304, f. 240r; transcription and encoding by Mina Monier. SNSF MARK16 ©CC BY-4.0.
GA 304, f. 240r; transcription and encoding by Mina Monier. SNSF MARK16 ©CC BY-4.0. VL 1, f. 40v; [75] transcription by Mina Monier and Claire Clivaz, based on the MS and on Wordsworth et al. edition; [76] encoding by Mina Monier; SNSF MARK16 CC-BY-4.0.
VL 1, f. 40v; [75] transcription by Mina Monier and Claire Clivaz, based on the MS and on Wordsworth et al. edition; [76] encoding by Mina Monier; SNSF MARK16 CC-BY-4.0.3. MARK16: Transcription and Encoding
3.1 Maintaining Balance between Data and Visualization
 GA 019, f. 113r. Transcribed and encoded by Mina Monier; © 2019 SNSF MARK16 Project. This work is licensed under a Creative Commons Attribution 4.0 Unported License. [88]
GA 019, f. 113r. Transcribed and encoded by Mina Monier; © 2019 SNSF MARK16 Project. This work is licensed under a Creative Commons Attribution 4.0 Unported License. [88] 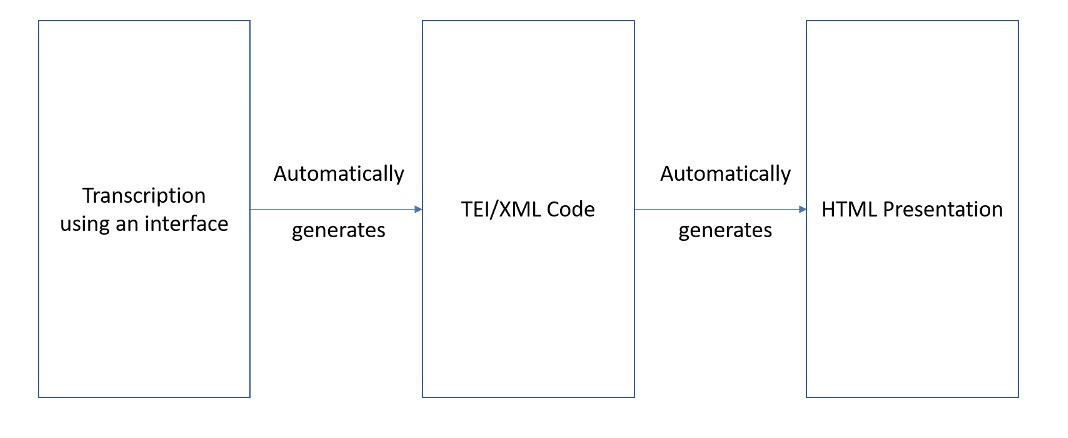 Interface transcription
Interface transcription MARK16 Encoding Process
MARK16 Encoding Process