0. Introduction
1. Pliny the Elder and statistical tools
1.1 Pliny the Elder and the language of science
1.2 The L.A.S.L.A., HyperbaseWeb, and the second book of the Natural History
A recent study by Poudat and Landragin [21] offers a complete description of methods and instruments available for corpus-based research, showing the number of options available to every scholar, and giving indications about which methods are preferable depending on the nature of the research. I therefore recommend this reading for a more complete description of corpus-based research, while I will focus only on tools which are useful for this specific study.
- Search
- The “Search” instrument allows users, not only to find a specific form surrounded by a certain span of text (that can be selected by the user), but also to search for all the forms corresponding to a certain morphological analysis (for instance all the substantives of the second declination) and all the forms deriving from a certain lemma. [22] The user can also look for sequences combining forms, lemmata, codes, and unspecified words.
- Theme or specific co-occurrents
- This function allows the user to find the co-occurrents of a certain form, lemma, or morphological code. The user can indicate the span of text considered for co-occurrence: a paragraph might be chosen for thematic research, while a sentence might be more appropriate for a strictly linguistic analysis. The user can choose as well if the co-occurrence will be calculated considering the lemmata, the forms, or the code of the words included in the span. Finally, the user can decide to filter the results, taking into account—for the calculations—only some grammatical categories (for example the verbs, or the substantives, etc.). [23] HyperbaseWeb shows also the co-occurrents of second degree, i.e. words that are co-occurrent of those being considered. [24]
- Distribution
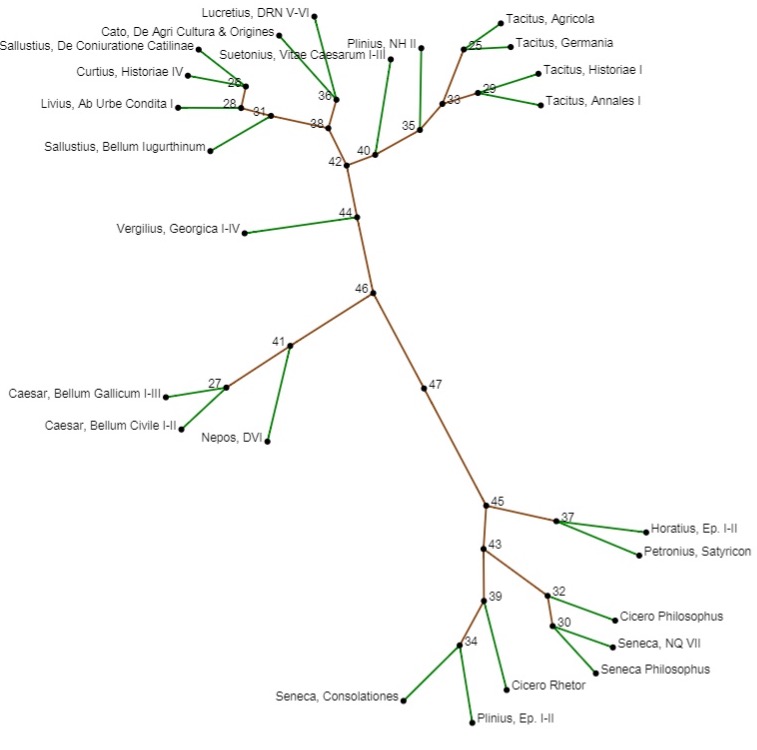
- The distribution tool combines different kind of functions whose aim is to show how linguistic features are distributed in a corpus formed by several texts. In particular, through the calculation of the z-score, it is possible to show which grammatical or lexical features differentiate each part of the corpus. [25] The results can be visualized as a histogram, which can display the z-score, the absolute frequency or the relative frequency of a certain form, lemma, or code. The program can also generate a Correspondence Analysis (CA), representing on a Cartesian graph the relative positions of text and features (or terms) in order to highlight oppositions or, on the contrary, correlations among parts of the corpus, [26] based on the words or grammatical categories chosen by the scholar. Another available graphical representation is the tree-analysis, which organizes in branches either the texts of the group or the categories chosen on the basis of the proximity to/distance from every other element. The number indicated on the node shows the priority in the grouping of elements. The distance dividing one element from another (measured by following the branches) indicates the distance between the twos. [27]
2. Seneca’s Natural Questions and Pliny’s Natural History
2.1 Statistical Data
Natural History and the seventh book of the Natural Questions.

Let us compare, as an example, two paragraphs in order to sketch out the differences between the two authors. In order to identify comparable sentences, we will choose a passage in which both authors deal with the movement of rapid winds. Even though both the paragraphs treat the atmospheric phenomenon of “accidental winds,” the reasons why the subject is brought up in the text are distinct. While Pliny provides a systematic description of all of the atmospheric phenomena, which includes typhoons, etc., Seneca, focuses on the confutation of Epigenes theory of the origin of comets, which states that they might arise out of cyclones. Pliny insists on the actual description of the landscapes and the natural elements that cause the formation of storms; Seneca’s paragraph is, on the contrary, focused on the necessity of showing that the evolution of cyclones prevents the possibility that comets might originate from them:
We also find in Seneca a rhetorical question, which is clearly a way of convincing the reader. Another striking element is the absence, in Seneca, of relative clauses. Now let us see now how Pliny deals with the subject:
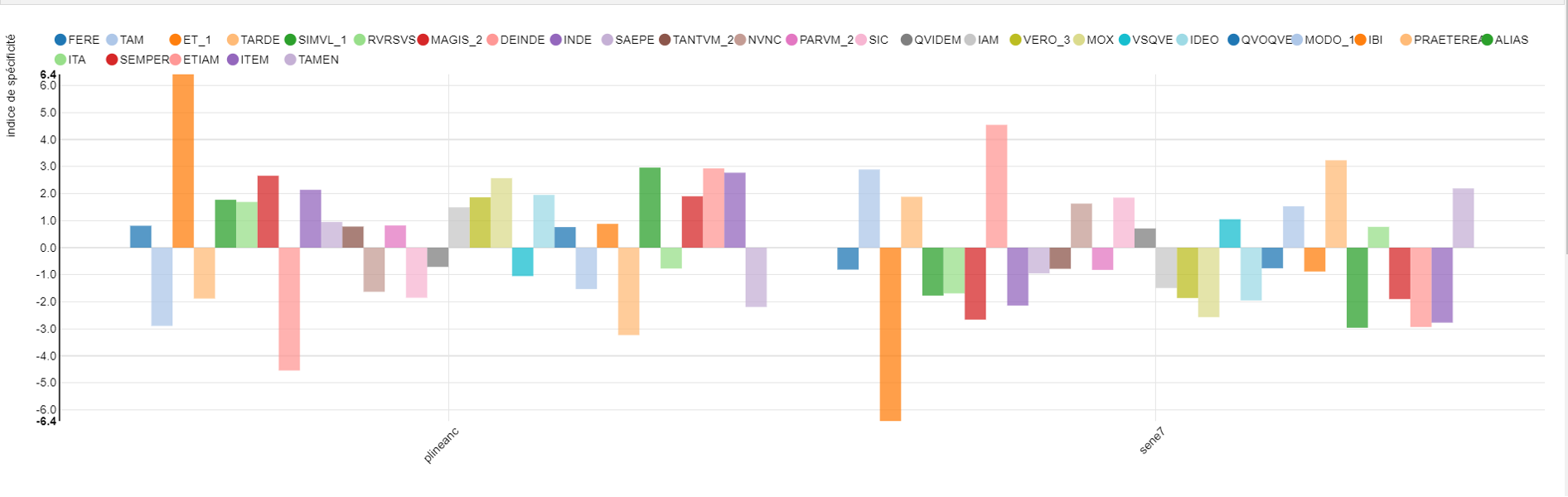
The TLL proposes four categories to describe how the adverbial et can be used: additive, cumulative, iuncturae, singularia. Because the research tool enables search for a specific lemma, we can find directly all occurrences of the adverbial et (LEM: ET_1) in Pliny’s text. Many examples of et follow a conjunction or an adverb. In this case the first particle determines the ‘role’ of the added element: for instance, in sed et (uero et) the added element contrasts, somewhat, with the previous one, [43] or quin et adds an element that emphasizes what has just been written; [44] ideo et announces that the added element is a consequence of what was stated in the previous sentence. [45] Contrary to Pliny’s usage, we never find such a combination of words in Seneca. The TLL considers iuncturae to include also the group ‘et + possessive pronoun/adjective’, which we found in our text. This group is specialized in the expression of one concept: that an event, phenomenon, took place also in contemporary times: [46]
This schema is interesting because it reinforces the credibility and meaning of the notions just described: that Pliny’s epoch also witnessed such events, on one side, stands as a proof of what he says, and, on the other, cues the reader to consider such ‘abstract’ material in the frame of his own experience.
Pliny always uses unde et to introduce an etymology, adding information (the name), then linking it to the previous phrase by means of the etymology. His intent is similar to what we have already seen: the name of the phenomenon (or the river) guarantees the validity of what has just been said and links the information to something familiar to the reader. This expression is typical of the entirety of Natural History, representing therefore a “plinian feature” (we found the expression unde et nomen at Natural History IV 65, V 73, VIII 218, etc., especially in botanical books [53] ). While Pliny is the first to employ the expression unde et nomen to introduce an etymology, the expression would subsequently be used by different authors (Cyprian, Ambrose, Augustine, Cassiodorus), and it is regularly found in Isidorus’ Etymologiae. We see therefore how the high rate of adverbial et is partly explained by the use of some recurring expressions necessary to Pliny’s informative aim. The expressions become part of the technical language, a kind of formula for introducing certain information.
3. Conclusions: Natural History II, Natural Questions VII, and other literary genres
The second point implies the re-consideration of Pliny’s title Natural History. We have already mentioned the complexity behind the term Historia, but an interesting analysis carried out by P. Jal [59] underlines how the title might hint at a new conception of history:
We have seen that the linguistic features that we have analyzed are often explained by the necessity to convey as much information as possible drawn from a wide range of sources; to provide the reader with non-hierarchical data, leaving them to the users’ interpretation; to link ‘remote material’ to the readers’ present reality. These concerns were partly shared by historians; on the contrary, both philosophers and rhetoricians are interested in convincing the audience through a precise process of reasoning, which brings strict organization to the speech or selection of material. This AFC (Figure 7), indeed, shows that the elements which characterize the oppositions along the principal axis are those mentioned before: for historical texts and the Natural Questions, substantives (which have an important weight in determining the first axis, 30%), adjectives, adverbs, coordinating particles; for philosophical and rhetorical texts, verbs and all the elements providing an interaction with the reader (interrogative particles, interjections, etc.)

Bibliography
Appendix: statistical data
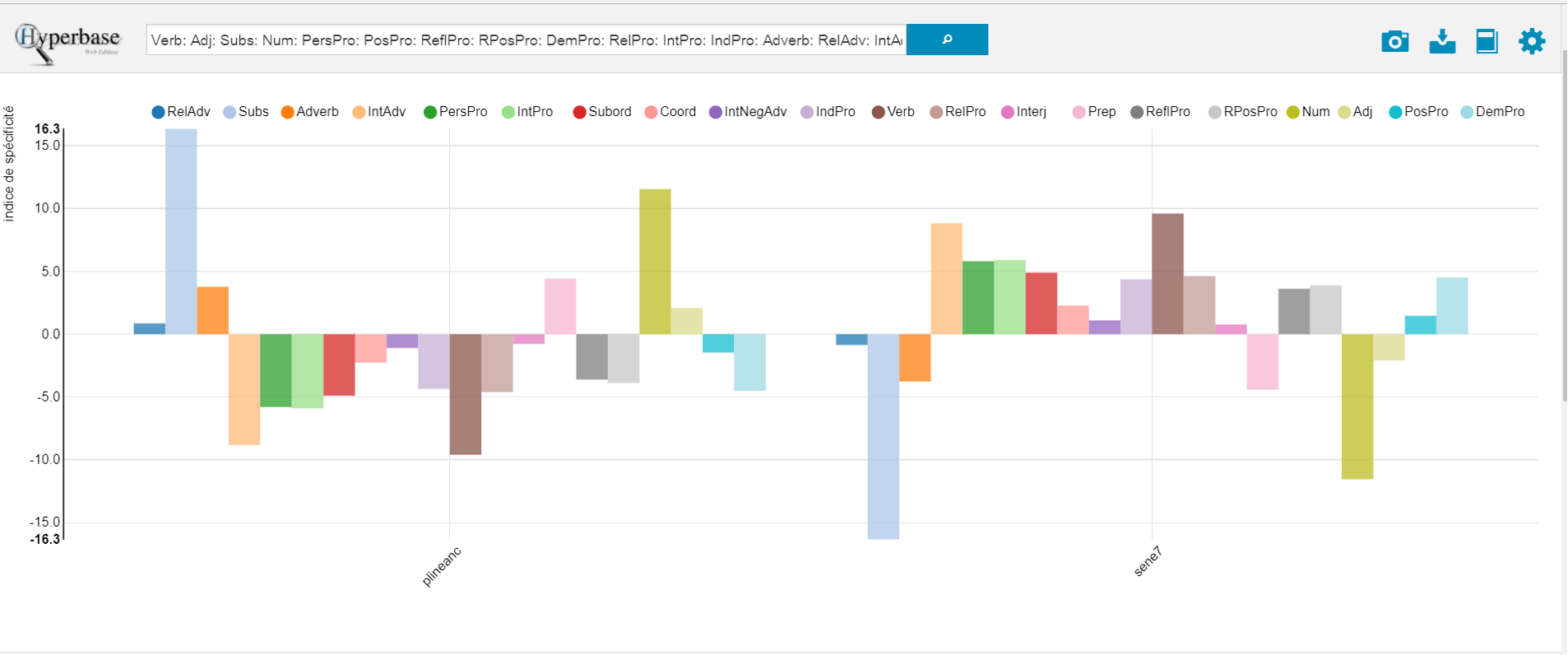
1. Distribution (z-score) of parts of speech between Natural History II and Natural Questions VII (Figure 1).
| Word | meta0:plineanc | meta0:sene7 |
| RelAdv | 0.86 | -0.86 |
| Subs | 16.34 | -16.34 |
| Adverb | 3.77 | -3.77 |
| IntAdv | -8.83 | 8.83 |
| PersPro | -5.8 | 5.8 |
| IntPro | -5.9 | 5.9 |
| Subord | -4.9 | 4.9 |
| Coord | -2.28 | 2.28 |
| IntNegAdv | -1.1 | 1.1 |
| IndPro | -4.36 | 4.36 |
| Verb | -9.6 | 9.6 |
| RelPro | -4.62 | 4.62 |
| Interj | -0.77 | 0.77 |
| Prep | 4.42 | -4.42 |
| ReflPro | -3.61 | 3.61 |
| RPosPro | -3.89 | 3.89 |
| Num | 11.55 | -11.55 |
| Adj | 2.09 | -2.09 |
| PosPro | -1.46 | 1.46 |
| DemPro | -4.51 | 4.51 |
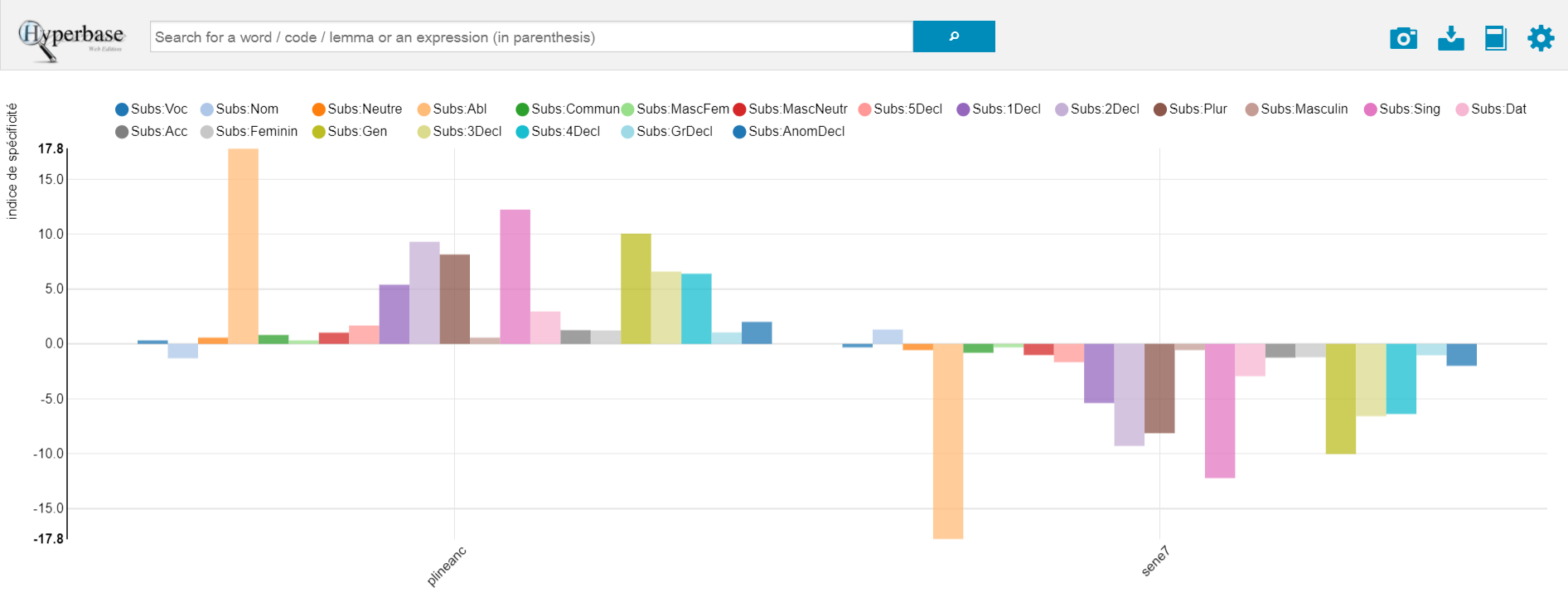
2. Distribution (z-score) of nouns categories between Natural History II and Natural Questions VII (Figure 2).
| Word | meta0:plineanc | meta0:sene7 |
| Subs:Voc | 0.32 | -0.32 |
| Subs:Nom | -1.31 | 1.31 |
| Subs:Neutre | 0.57 | -0.57 |
| Subs:Abl | 17.78 | -17.78 |
| Subs:Commun | 0.81 | -0.81 |
| Subs:MascFem | 0.32 | -0.32 |
| Subs:MascNeutr | 1.02 | -1.02 |
| Subs:5Decl | 1.67 | -1.67 |
| Subs:1Decl | 5.39 | -5.39 |
| Subs:2Decl | 9.3 | -9.3 |
| Subs:Plur | 8.14 | -8.14 |
| Subs:Masculin | 0.57 | -0.57 |
| Subs:Sing | 12.23 | -12.23 |
| Subs:Dat | 2.95 | -2.95 |
| Subs:Acc | 1.25 | -1.25 |
| Subs:Feminin | 1.22 | -1.22 |
| Subs:Gen | 10.04 | -10.04 |
| Subs:3Decl | 6.59 | -6.59 |
| Subs:4Decl | 6.39 | -6.39 |
| Subs:GrDecl | 1.04 | -1.04 |
| Subs:AnomDecl | 2 | -2 |
3. Distribution (absolute frequency) of nouns cases between Natural History II and Natural Questions VII (Figure 3).
| Word | meta0:plineanc | meta0:sene7 | Total |
| Subs:Nom | 1080 | 405 | 1485 |
| Subs:Acc | 1399 | 478 | 1877 |
| Subs:Dat | 207 | 48 | 255 |
| Subs:Gen | 1128 | 208 | 1336 |
| Subs:Abl | 1939 | 284 | 2223 |
4. Distribution (z-score) of verbal categories between Natural History II and Natural Questions VII.
| Word | meta0:plineanc | meta0:sene7 |
| Verb:PqPerfPeri | 0 | 0 |
| Verb:Sup-u | 2.13 | -2.13 |
| Verb:Inf | -1.56 | 1.56 |
| Verb:Act | -13.53 | 13.53 |
| Verb:Ind | -13.41 | 13.41 |
| Verb:VerbAdj | -1.17 | 1.17 |
| Verb:Subj | -7.37 | 7.37 |
| Verb:1Conj | 2.1 | -2.1 |
| Verb:AnomConj | -10.54 | 10.54 |
| Verb:Dep | 1.78 | -1.78 |
| Verb:Perf | 1.09 | -1.09 |
| Verb:Pres | -8.78 | 8.78 |
| Verb:3Conj | -2.74 | 2.74 |
| Verb:Imper | -2.04 | 2.04 |
| Verb:MixConj | -1.12 | 1.12 |
| Verb:2Conj | -7.38 | 7.38 |
| Verb:Imp | -6.85 | 6.85 |
| Verb:PqPerf | -1.1 | 1.1 |
| Verb:Fut | -4.37 | 4.37 |
| Verb:4Conj | -1.21 | 1.21 |
| Verb:FutPerfPeri | 0 | 0 |
| Verb:2Pers | -5.88 | 5.88 |
| Verb:Part | 8.58 | -8.58 |
| Verb:3Pers | -14.33 | 14.33 |
| Verb:Gerund | 1.26 | -1.26 |
| Verb:PerfPeri | 0.32 | -0.32 |
| Verb:1Pers:1Pers | -4.73 | 4.73 |
| Verb:Sup um:Sup-um | 0.32 | -0.32 |
| Verb:SemiDep | -0.99 | 0.99 |
| Verb:FutPerf | -2.04 | 2.04 |
| Verb:Pas | 2.98 | -2.98 |
5. Distribution (z-score) of 30 more frequent adverbial lemmata between Natural History II and Natural Questions VII (Figure 4).
| Word | meta0:plineanc | meta0:sene7 |
| LEM:FERE:Adverb | 0.81 | -0.81 |
| LEM:TAM:Adverb | -2.89 | 2.89 |
| LEM:ET_1:Adverb | 6.41 | -6.41 |
| LEM:TARDE:Adverb | -1.88 | 1.88 |
| LEM:SIMVL_1:Adverb | 1.77 | -1.77 |
| LEM:RVRSVS:Adverb | 1.69 | -1.69 |
| LEM:MAGIS_2:Adverb | 2.66 | -2.66 |
| LEM:DEINDE:Adverb | -4.54 | 4.54 |
| LEM:INDE:Adverb | 2.14 | -2.14 |
| LEM:SAEPE:Adverb | 0.95 | -0.95 |
| LEM:TANTVM_2:Adverb | 0.78 | -0.78 |
| LEM:NVNC:Adverb | -1.63 | 1.63 |
| LEM:PARVM_2:Adverb | 0.82 | -0.82 |
| LEM:SIC:Adverb | -1.85 | 1.85 |
| LEM:QVIDEM:Adverb | -0.71 | 0.71 |
| LEM:IAM:Adverb | 1.49 | -1.49 |
| LEM:VERO_3:Adverb | 1.86 | -1.86 |
| LEM:MOX:Adverb | 2.57 | -2.57 |
| LEM:VSQVE:Adverb | -1.05 | 1.05 |
| LEM:IDEO:Adverb | 1.95 | -1.95 |
| LEM:QVOQVE:Adverb | 0.76 | -0.76 |
| LEM:MODO_1:Adverb | -1.53 | 1.53 |
| LEM:IBI:Adverb | 0.88 | -0.88 |
| LEM:PRAETEREA:Adverb | -3.23 | 3.23 |
| LEM:ALIAS:Adverb | 2.96 | -2.96 |
| LEM:ITA:Adverb | -0.77 | 0.77 |
| LEM:SEMPER:Adverb | 1.9 | -1.9 |
| LEM:ETIAM:Adverb | 2.93 | -2.93 |
| LEM:ITEM:Adverb | 2.77 | -2.77 |
| LEM:TAMEN:Adverb | -2.19 | 2.19 |
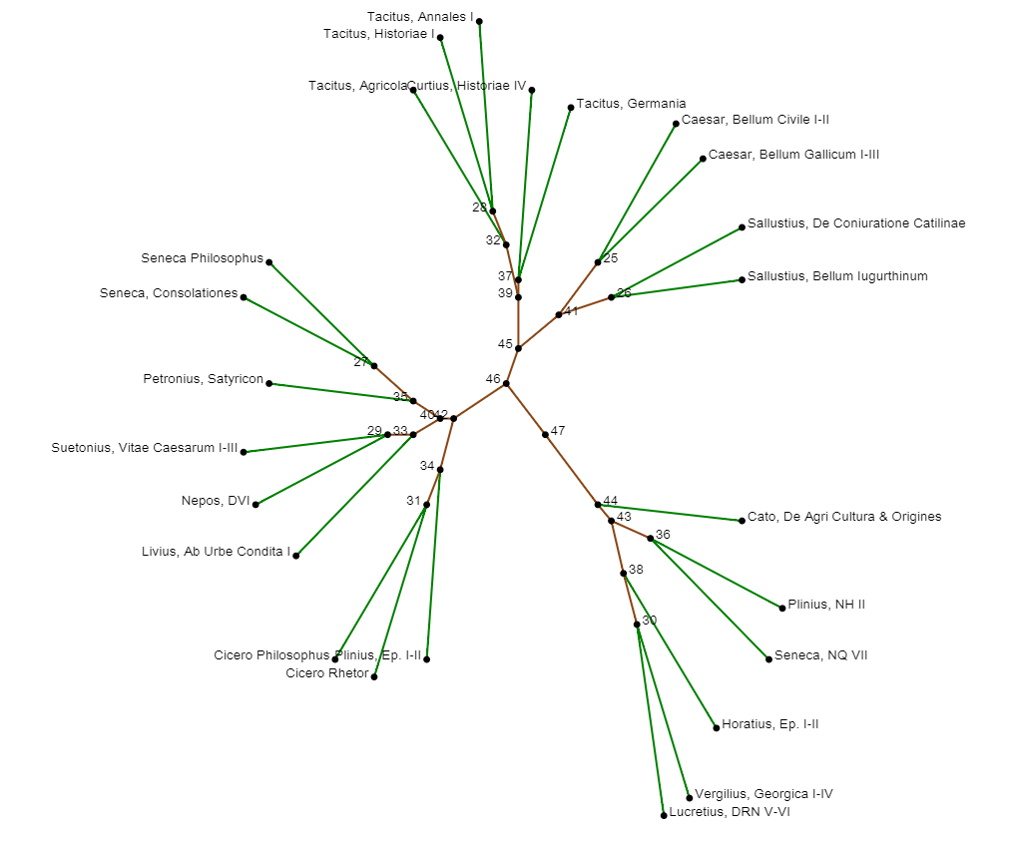
6. Distribution (z-score) of adverbial et in literary database.
| Plinius, Ep. I-II | 0.97 | Nepos, DVI | -9 | |
| Horatius, Ep. I-II | -2.44 | Suetonius, Vitae Caesarum I-III | 12.05 | |
| Curtius, Historiae IV | -1.24 | Sallustius, De Coniuratione Catilinae | -4.43 | |
| Petronius, Satyricon | 2.49 | Sallustius, Bellum Iugurthinum | -6.54 | |
| Cicero Rhetor | -6.1 | Tacitus, Agricola | -0.72 | |
| Cicero Philosophus | -5.33 | Tacitus, Historiae I | 0.85 | |
| Seneca, Consolationes | -0.88 | Tacitus, Annales I | -2.08 | |
| Seneca Philosophus | -0.83 | Tacitus, Germania | 6.03 | |
| Livius, Ab Urbe Condita I | 1.37 | Cato, De Agri Cultura & Origines | -6.49 | |
| Caesar, Bellum Civile I-II | -6.18 | Plinius, NH II | 16.07 | |
| Caesar, Bellum Gallicum I-III | -6.33 | Seneca, NQ VII | -1.23 | |
| Vergilius, Georgica I-IV | 0.86 | Lucretius, DRN V-VI | -5.13 |